

Stable Diffusion Review 2025: In-Depth Analysis of Generative AI Image-Making Model
Stable Diffusion is an AI model that creates stunning, professional-grade images from simple text prompts. In this blog, we’ll dive into what makes it special, how it works & how to install in Windows, its amazing features, benefits and why it’s a game-changer for artists, designers, and anyone who loves creating visuals.

What is Stable Diffusion?
Stable Diffusion is a deep learning, text-to-image generative artificial intelligence (AI) model released in 2022 that creates detailed, photorealistic images from text descriptions or prompts. It is based on diffusion techniques and latent diffusion models, which allow it to generate images by iteratively denoising a latent representation of an image. Unlike earlier proprietary models such as DALL-E-3 and Midjourney, Stable Diffusion’s code and model weights are publicly available, enabling it to run efficiently on consumer-grade hardware with modest GPU requirements (as low as 2.4 GB VRAM).
Besides text-to-image generation, it can also perform related tasks like inpainting, outpainting, and image-to-image translation guided by text prompts. Its architecture includes components such as a variational autoencoder, forward and reverse diffusion processes, a noise predictor using a U-Net convolutional neural network, and text conditioning via a CLIP tokenizer and transformer.
Founder of Stable Diffusion?
Stable Diffusion was developed by Stability AI, a UK-based artificial intelligence company co-founded in 2019 by Mohammad Emad Mostaque and Cyrus Hodes. The model itself originated from research projects called Latent Diffusion, developed by researchers at Ludwig Maximilian University of Munich and Heidelberg University, including Robin Rombach, Andreas Blattmann, Patrick Esser, and Dominik Lorenz, who later joined Stability AI to continue development.
Emad Mostaque’s vision was to create accessible AI tools that empower users by making powerful generative AI models publicly available and open source, breaking away from the closed, cloud-only models of the past.

Best Features of Stable Diffusion
This AI image generator is packed with innovative features that enhance its versatility. Here are ten standout features:
High-Quality Image Generation
Produces detailed, photorealistic, or artistic images with fine control over styles, trained on massive datasets like LAION-5B.
Text-to-Image Generation
It can generate high-quality images from textual prompts, allowing users to create diverse visuals by adjusting parameters like seed numbers and denoising schedules.
Image-to-Image Generation
Users can input an image along with a text prompt to create variations or enhancements based on the original image, such as turning sketches into detailed images.
Inpainting and Image Editing
It supports editing parts of images by masking areas and generating new content, useful for photo retouching, object removal, or adding new elements.
Variational Autoencoder (VAE) Architecture
It compresses images into a latent space for efficient processing and then decodes them back into high-resolution images, reducing computational load.
U-Net Noise Predictor
A convolutional neural network that iteratively denoises latent images guided by text prompts, ensuring high fidelity and detail in outputs.
Text Conditioning via CLIP Tokenizer
Converts text prompts into embeddings that guide image generation, supporting up to 75 tokens per prompt for nuanced control.
Support for High Resolutions
Later versions support up to 768×768 pixels and beyond, enabling detailed and crisp images.
Open Source and Customizability
The model is open source, allowing developers to create custom versions optimized for speed, memory, and specific use cases.
Lower Computational Requirements
Compared to other text-to-image models, it requires significantly less processing power and VRAM (minimum 6 GB VRAM recommended), enabling use on consumer-grade hardware.
Versatile Applications
Beyond static images, it supports graphic artwork, logo creation, video clip generation, animation, super-resolution, and semantic synthesis.
Why Choose Stable Diffusion?
Stable Diffusion is a popular choice for generating images from text prompts due to several reasons:
- Open-Source and Accessible: This generative AI is open-source, allowing developers and users to modify, customize, and integrate it into various applications without restrictive licensing. This fosters a large community of contributors and reduces costs compared to proprietary models.
- High-Quality Outputs: It produces detailed, photorealistic, or stylized images that rival or surpass other text-to-image models, thanks to its latent diffusion architecture trained on vast datasets like LAION-5B.
- Efficient Resource Use: Unlike models requiring massive computational power, it can run on consumer-grade GPUs (e.g., 4-8GB VRAM), making it accessible for hobbyists, researchers, and small-scale developers.
- Customizability: Users can fine-tune the model with custom datasets or use techniques like DreamBooth to create personalized models for specific styles or subjects, offering flexibility for niche applications.
- Local Deployment: It can be run locally, ensuring privacy and control over data, which is critical for sensitive applications compared to cloud-based proprietary alternatives.
- Community and Ecosystem: A robust ecosystem of tools (e.g., AUTOMATIC1111’s web UI, Gradio interfaces) and active community support make it easier to use, extend, and troubleshoot.
- Versatility: It supports a wide range of applications, from art generation to inpainting, outpainting, and image-to-image transformations, making it suitable for creative, commercial, or research purposes.
- Cost-Effective: Being free to use and deploy, it’s a cost-effective alternative to paid services like DALL·E or Midjourney, especially for high-volume or experimental projects.
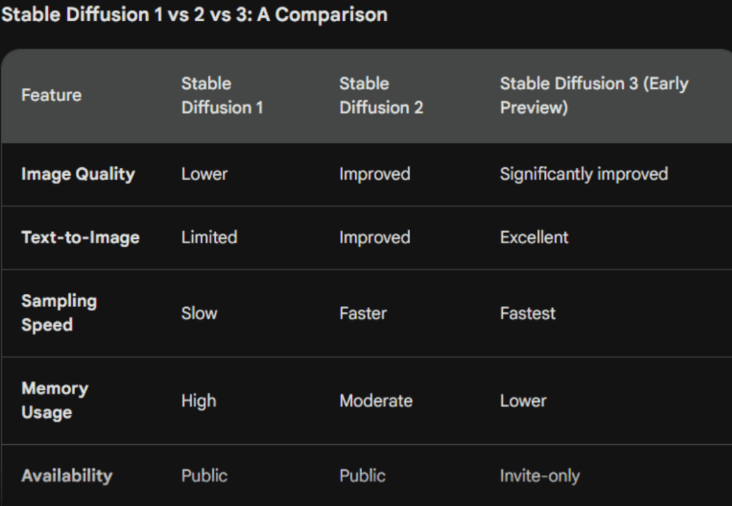
Top Benefits of Stable Diffusion
Stable Diffusion is a leading AI art generator that transforms text prompts into stunning, professional-grade images. It offers unique advantages that make it a standout in generative AI. Here are the key benefits:
High-Quality, Realistic Image Generation
It produces highly detailed and realistic images that closely match textual prompts, supporting a variety of visual styles from photorealistic portraits to abstract art.
Flexibility and Customizability
Users can control key parameters like denoising steps and noise levels, input text prompts or rough sketches, and fine-tune the model for domain-specific applications, enabling diverse creative outputs and tailored workflows.
Wide Range of Applications
Beyond text-to-image generation, it supports image-to-image generation, graphic artwork, logo creation, image editing and retouching, and even video creation and animation.
Enhanced Creative Possibilities
It enables artists, designers, and content creators to explore new styles and generate unique visuals that were previously difficult or impossible to produce.
Accessible Across Platforms
Stable Diffusion online and AI app options, including ai android, allow users to create images effortlessly. This platforms hugging-face provide free access, making it ideal for all skill levels.
Prompt Adherence and Speed
The model delivers competitive inference speed and strong adherence to user prompts, ensuring relevant and high-quality outputs.
Scalability and Integration
It supports scalable solutions from small projects to enterprise-level deployments and offers flexible API integration for seamless workflow enhancement.
Open-Source and Cost-Effective
Available on github, this neural image generator is open-source, with download options for local use. Models like 2 and 3 reduce costs for non-commercial projects, unlike proprietary alternatives.
Highly Customizable Outputs
AI art generator models, such as xl, support fine-tuning for styles like anime or art. Tools like automatic1111 enable precise control with minimal input.
Efficient Processing
The architecture uses latent diffusion, enabling download to run on GPUs with just 4GB VRAM. This makes the image generator accessible without high-end hardware.
Diverse Creative Applications
From AI video generator to AI blender for 3D modeling, it supports architecture and more, catering to varied creative needs.
Innovation and Business Benefits
For organizations, adopting development practices can improve system stability, accelerate time-to-market for digital solutions, increase innovation, and optimize costs and resources
Using Stable Diffusion Online
If you want to experiment without installation, you can use this AI tool directly on the web. Simply visit the website i.e. stable diffusion web, type in your text, and click “generate” to see four different images based on your prompt. However, installing it locally gives you more control over parameters and allows for batch image outputs.
How to Download & Install Stable Diffusion in Windows?
Step 1: Clone the Repository
Step 2: Download the Model/Checkpoint
Step 3: Update to the Latest Version
Step 4: Launch Stable Diffusion
Step 5: Access the Web Interface
System Requirements
Before installation, ensure your PC meets the following requirements:
Pre-Requisites for Installation
Install Git
Install Python
How to Use Stable Diffusion?
In this guide:
Step 1. Using Text-to-Image
Step 2: Experiment and Explore
Step 3: Training Your Own Model (LoRA Models)
LoRA (Low-Rank Adaptation) allows you to fine-tune models for specific characters or styles. Here’s how to train your own:
Step 4: Using ControlNet
ControlNet offers fine-grained control over image generation, allowing for more detailed and specific outputs. Here’s a quick overview:
Step 5: Save and Share
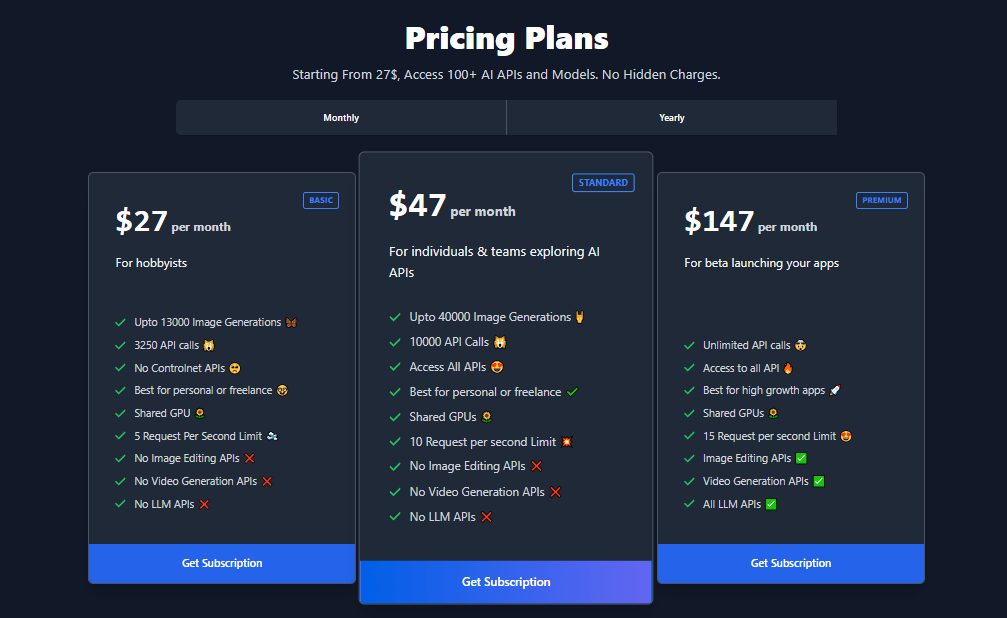
Pricing Of Stable Diffusion for Both APK and Online
| Plan Type | Price (USD) | Image Generations / Usage Limits | Features | Target Users |
| Basic | $27/month | Up to 13,000 image generations, 3,250 API calls | Shared GPU 5 requests/sec limit No ControlNet No image/video editing APIs | Hobbyists Personal Freelance |
| Standard | $49/month | Up to 40,000 image generations, 10,000 API calls | Shared GPU10 requests/sec limit Access to all APIs No image/video editing APIs | Individuals Teams exploring AI |
| Premium | $149/month | Unlimited API calls | Shared GPU 15 requests/sec limit Includes image editing Video generation, and LLM APIs | High growth apps Enterprises |
| Web-based Free Plan | Free | Limited daily images (e.g., 10 images/day) | Watermarked images Basic tools | Casual users |
| Web-based Pro Plan | Approx. €13/month (~$14) | 2,000 to 4,000 images/month | Faster processing No ads/watermarksCommercial license Image upscaling | Advanced users Professionals |
| Self-Hosting | Free (software) | Depends on user hardware | Full access to open-source code Requires own GPU hardware and technical skills | Tech-savvy users Researchers |
Who can Use Stable Diffusion?
The targeted audience for this latent diffusion is broad and diverse, including:
Artists and Creatives: Digital artists, illustrators, designers, and content creators use this platform to generate concepts, sketches, storyboards, and unique artwork across various styles, enhancing their creative workflows.
Businesses and Marketers: Advertising agencies, marketing teams, and brands leverage this generative AI to produce on-brand marketing assets, social media visuals, product images, and lifestyle scenes, reducing costs associated with traditional photoshoots and enabling targeted campaigns.
Developers and AI Researchers: Developers build custom AI applications, fine-tune models for niche domains, and integrate AI art generator into software solutions. Researchers use it for innovative applications including medical imaging and scientific visualization.
Fashion and Product Designers: Designers experiment with colors, prints, and product concepts digitally, accelerating ideation and client presentations.
Educators and E-Learning Providers: They use it to create engaging educational materials, illustrations, and tailored visuals to enhance learning experiences.
General Public and Hobbyists: Due to its accessibility on consumer hardware and open-source availability, millions of users worldwide from casual hobbyists to enthusiasts—explore this AI art generator for personal projects, art, and entertainment.
Enterprises and High-Growth Applications: Organizations integrate this AI visual synthesis for scalable content generation, video creation, animation, and advanced AI-powered media production.
For users interested in expanding their creativity, tools like MioCreate AI and ReMaker AI offer additional features such as face-swapping and visual editing, making them a great complement to Stable Diffusion’s image generation capabilities.
Best Alternatives to Stable Diffusion
Midjourney
Midjourney is a top AI image generator known for producing highly stylized, imaginative artwork, especially excelling in fantasy, sci-fi, and surreal imagery. It operates primarily through Discord, making it user-friendly without coding skills. Midjourney offers various subscription plans starting at $10/month, with options for upscaling and aspect ratio customization. It boasts a strong and active community, ideal for artists and creatives seeking unique visual styles.
DALL·E 3 (OpenAI)
DALL·E 3 delivers photorealistic and detailed images from text prompts, with advanced features like outpainting and inpainting. Integrated with ChatGPT Plus and available via API, it suits users needing realistic visuals for marketing, education, or creative projects. Pricing is included with ChatGPT Plus or pay-as-you-go API fees.
Adobe Firefly
Adobe Firefly integrates seamlessly with Adobe Creative Cloud, offering AI-powered image generation, generative fill, and text-to-vector graphics. It supports ethical AI training data and is perfect for professionals who want to enhance their existing Adobe workflows. Pricing ranges from a free plan to $59.99/month for full Creative Cloud access.
FLUX.1
Developed by former Stability AI team members, FLUX.1 is an open-source model under the Apache 2.0 license, offering powerful and competitive image generation quality. It is gaining popularity in the AI art community and is accessible via platforms like NightCafe and Tensor.Art. Pricing depends on the platform, often with free credits to try.
Stablecog
Stablecog is a free, multilingual, and open-source AI image generator. It is user-friendly and privacy-focused, making it suitable for casual users and hobbyists who want easy access to text-to-image generation without complex setup.
ModelsLab
ModelsLab provides advanced AI capabilities through APIs, including fine-tuned Stable Diffusion DreamBooth models. It supports image editing, chatbot development, and voice replication, targeting developers and businesses needing customizable AI solutions.

Conclusion
Stable Diffusion is a game-changer in AI image generation—powerful, accessible, and incredibly versatile. Whether you’re an artist, developer, or business, it lets you create stunning, high-quality images quickly and easily, even on regular hardware. With continuous improvements and a vibrant ecosystem, it unlocks endless creative possibilities and fuels innovation like never before. Simply put, it’s the go-to tool for anyone ready to bring their imagination to life with AI.
FAQs
What is Stable Diffusion?
Stable Diffusion is an open-source latent text-to-image diffusion model that generates high-quality, photorealistic images from textual descriptions or existing images by gradually denoising a latent representation.
How does Stable Diffusion work?
It starts with random noise and iteratively removes noise guided by a neural network (U-Net) conditioned on the text prompt, working in a compressed latent space for efficiency. A Variational Autoencoder (VAE) then decodes the latent image into a high-resolution output.
What models does Stable Diffusion use?
The latest widely used model is XL (SDXL), which has a larger UNet backbone and a second text encoder for better prompt understanding and image quality. There is also SDXL Turbo, a faster distilled version maintaining high fidelity.
Can I use Stable Diffusion for commercial purposes?
Yes! it is released under a permissive license allowing both commercial and non-commercial use of generated images.
What is the copyright status of images created with Stable Diffusion?
Images generated via Stable Diffusion Online fall under the CC0 1.0 Universal Public Domain Dedication, meaning they are free to use without copyright restrictions.
What hardware do I need to run Stable Diffusion?
It can run on consumer-grade GPUs with around 8 GB of VRAM, making it accessible without expensive infrastructure.
What are the main features of Stable Diffusion?
Key features include text-to-image generation, image-to-image transformation, inpainting (filling missing parts), outpainting (expanding images), fast inference, and support for fine-tuning and customization.
How can I access Stable Diffusion?
You can use this generative AI via local installation, web platforms, cloud services, or APIs provided by Stability AI and partners.
Is Stable Diffusion suitable for beginners?
Yes! there are many beginner-friendly tutorials, web interfaces, and community resources to help new users start generating images quickly.
What is the difference between SDXL and SDXL Turbo?
SDXL Turbo uses a new distillation technique (Adversarial Diffusion Distillation) to generate images in a single step, enabling real-time outputs with high quality, while SDXL 1.0 uses a multi-step diffusion process.





